Массовое сопоставление каталогов в Интеграме: автоматический подбор пар
Продолжаем тему сопоставления каталогов: массовый автоподбор в несколько потоков, как считается оценка точности, кандидаты-альтернативы, выгрузка в Excel и доуточнение шорт-листа языковой моделью — без программирования.
В прошлой статье — «Сопоставление каталогов продукции в конструкторе Интеграм» — мы показали базу: как за 15 минут загрузить два каталога, токенизировать наименования и получить первое сопоставление через пересечение токенов. И обещали разобрать массовый автоматический подбор пар для всего каталога. Выполняем обещание.
Напомним задачу. Есть свой каталог (SKU) и каталог контрагента (RFP) — по сути одни и те же позиции, но названные разными словами и с несовпадающими артикулами. Здесь это картриджи: 22 тысячи записей у контрагента против десятков тысяч наших. Обычно такое решают с помощью Elasticsearch, сложных алгоритмов нечёткого поиска и руками программистов. Мы делаем это на конструкторе Интеграм — без кода.
Загрузка по сохранённой настройке
Когда подход уже отлажен, рутина сводится к паре кликов. Идём в меню загрузки и выбираем заранее сохранённую настройку — Интеграм сам разбирает Excel: видит листы, понимает, какие данные брать, и показывает, сколько строк будет загружено. Догружаем очередную порцию каталога, проверяем сводную статистику и запускаем. Скорость — порядка 500–1000 записей в секунду.
Токенизация одним запросом
Загруженные записи поступают без токенов. Открываем вынесенный в меню запрос «Токенизация» — это инструкция Интеграму, как обработать данные: он берёт наименование и разбивает его на слова-токены. Нажимаем «Выполнить» — все новые записи токенизированы. То же самое делаем для второй таблицы (RFP) — токенизация RFP устроена так же.
Важно: обе таблицы наполняют один общий справочник токенов. Именно поэтому потом находятся пересечения между каталогами.
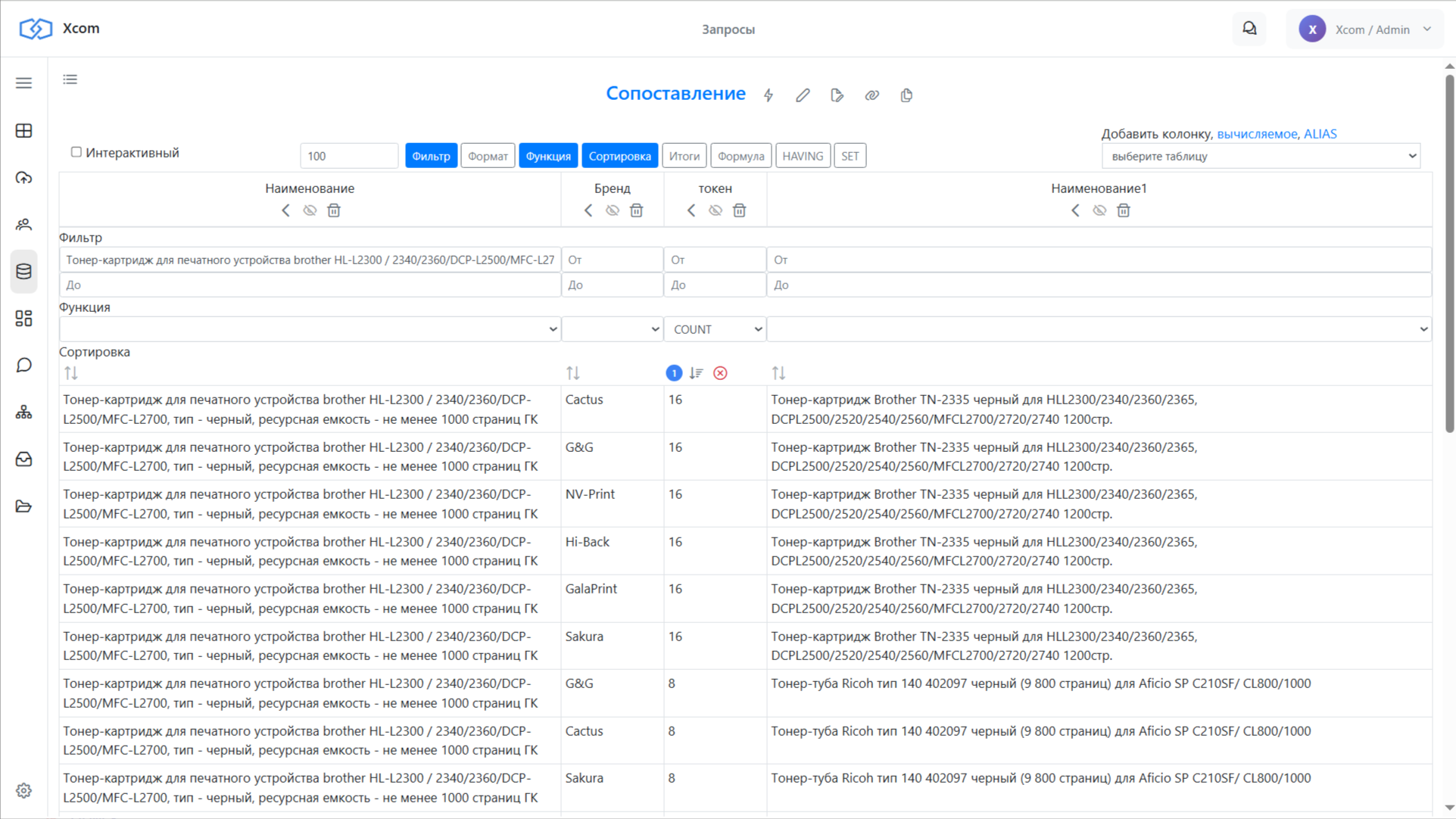
Рабочее место сопоставления
Дальше идём в меню сопоставления — это отдельное рабочее место. Выбираем позицию и по токенам подбираем к ней кандидатов из каталога-контрагента (или наоборот). Совпадения подсвечиваются: зелёным отмечены строки, где совпали марка, модель и тип устройства. Где-то зелёного нет — значит, что-то одно не совпало, но это решается настройкой: под каждый тип продукции мы задаём правила прямо в запросе, без программирования.
Массовый автоматический подбор
Самое интересное — режим массового подбора. Здесь видны все наименования из RFP, для которых ещё не подобран наш артикул. Нажимаем Start — запускается автоматический механизм, который в несколько потоков находит совпадения и записывает их. В таблице RFP начинают появляться подобранный артикул и альтернативные кандидаты, у лучшего варианта — самая высокая оценка.
Скорость — порядка 120 сопоставлений в минуту. Если запустить на все 22 тысячи позиций, за пару-тройку часов каталог будет обработан целиком. Механизм сам регулирует потоки.
Как считается оценка точности
У каждой пары есть числовая оценка — по ней пары и сортируются. Считается она из двух величин:
- количества совпавших токенов — сколько одинаковых слов в двух наименованиях;
- отношения их общей длины к длине наименования — насколько совпавшие слова «закрывают» позицию, а не оказались случайными короткими словами.
Формула нехитрая и полностью на виду. Её можно усложнять и оттачивать под конкретную номенклатуру: добавлять веса частым и редким токенам, требовать обязательного совпадения бренда и типа товара. Как размечать токены весами и флажками — мы разбирали в предыдущей статье.
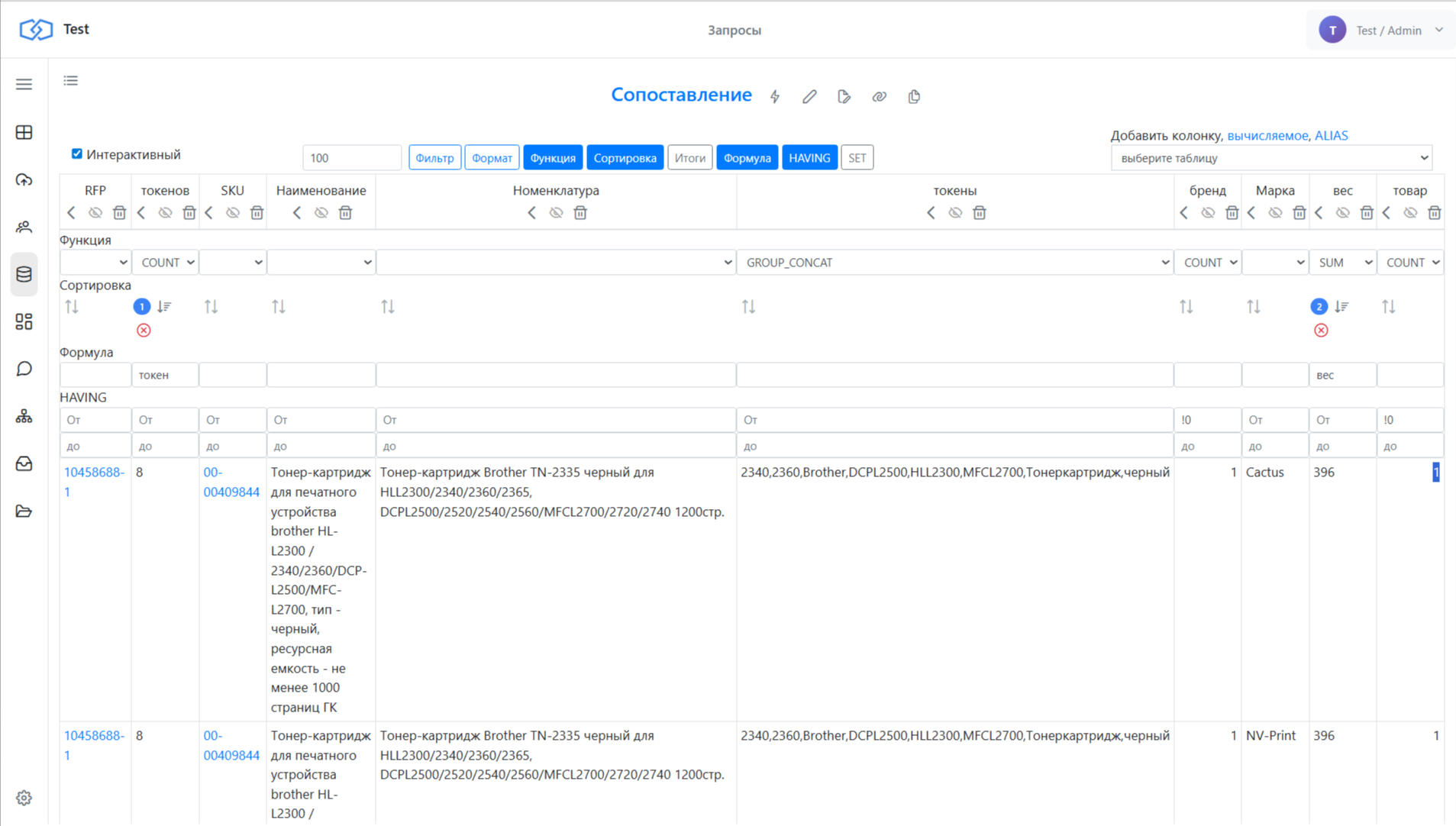
Кандидаты и выгрузка результата
Для каждой позиции контрагента видно не только лучшее совпадение, но и список кандидатов — тех, кто тоже подходит и кого ещё стоит проверить. Когда результат собран, его можно передать дальше: отдельный запрос собирает подобранный артикул и все альтернативы и выгружает данные, например, в Excel. На демонстрации из 22 тысяч строк механизм распознал больше 5300 позиций и сложил их в один большой файл.
То же самое доступно и программно — через JSON API, если результат нужно отдать во внешнюю систему.
Доуточнение языковой моделью
Когда объём данных невелик — это не перемножение сотен тысяч позиций на сотни тысяч, а, скажем, 22 тысячи строк, — итог можно дополнительно уточнить языковой моделью. Идея простая: тяжёлую часть делает токенное сопоставление и отдаёт по каждой позиции короткий список кандидатов, а модель из этого шорт-листа выбирает только то, что точно совпадает. Получается быстро, дёшево и точно — потому что модель работает уже по отобранным парам, а не по всему каталогу.
Итог
Сопоставление каталогов не обязано быть проектом с Elasticsearch и штатом разработчиков. На конструкторе Интеграм весь цикл — загрузка → токенизация → сопоставление → массовый автоподбор → проверка → выгрузка — собирается таблицами и запросами, без программирования. Регулярные выражения и разметку токенов за вас сделает ИИ, а спорные пары снимет доуточнение языковой моделью.
Подробнее об инструменте — на отдельной странице «Массовое сопоставление каталогов». А сравнение с Elasticsearch и заказной разработкой — в базе знаний.
Попробуйте на своих данных. Это гораздо проще, чем кажется, и гораздо быстрее, чем вручную.