Сопоставление каталогов продукции в конструкторе Интеграм
Как за 15 минут сопоставить десятки тысяч позиций из двух каталогов с разными названиями и артикулами, используя токенизацию и пересечение токенов без программирования.
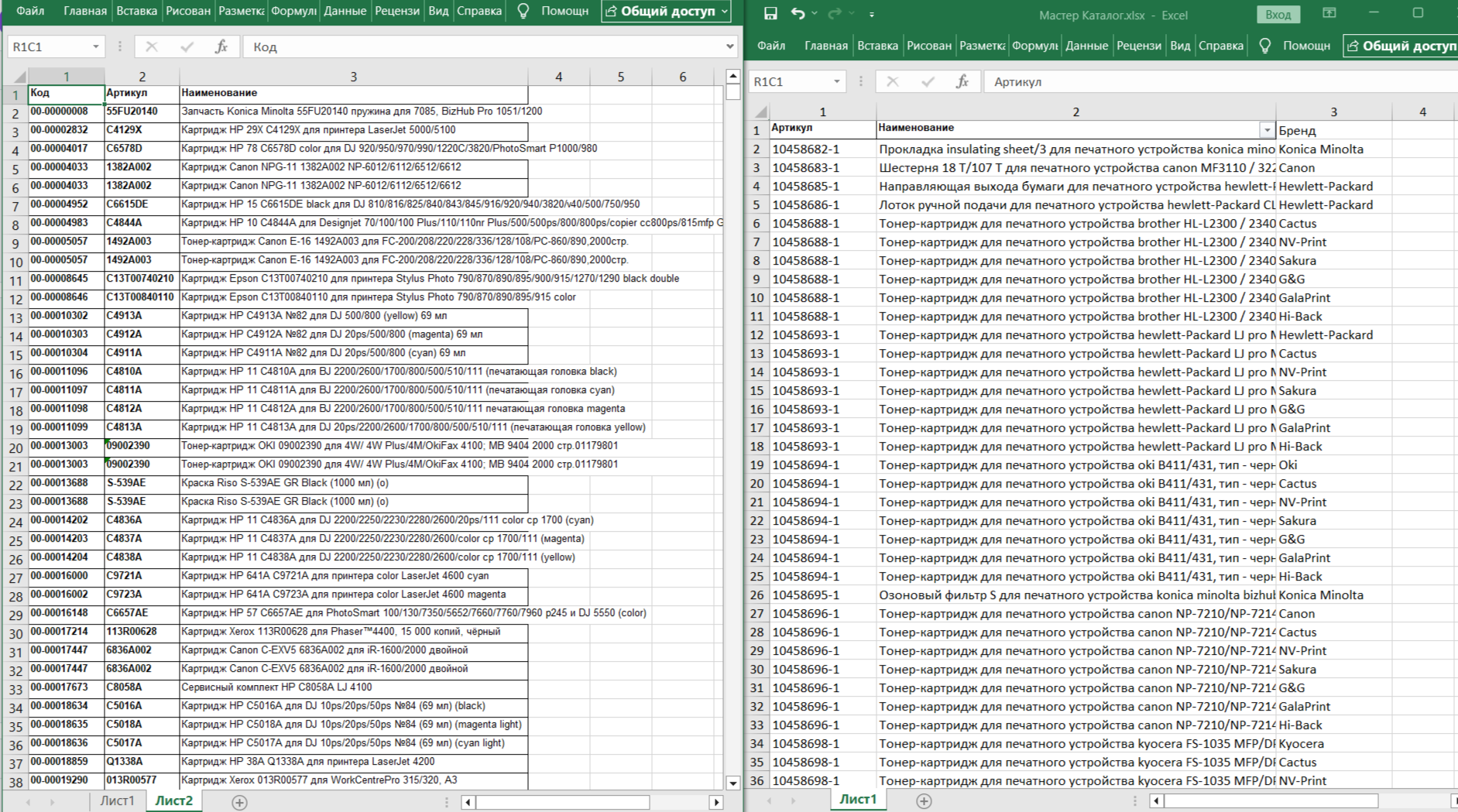
Перед вами непростая, но очень распространённая задача: нужно сопоставить два прайс-листа или каталога продукции. В них в свободном виде описана номенклатура — по сути, одни и те же позиции, но разными словами и с несовпадающими внутренними артикулами. В одном файле 28 тысяч записей, в другом — 22 тысячи. В полном объёме счёт может идти на сотни тысяч.
Обычно такие задачи решают с помощью Elasticsearch, сложных алгоритмов нечёткого поиска и руками программистов. Мы покажем, как это делается в Интеграме — быстро, без кода, с приемлемой точностью.
Стратегия сопоставления
Идея простая: разбиваем каждое название на отдельные слова (токены), а затем ищем записи, у которых набор токенов максимально пересекается. Это первое приближение — дальше логику можно усложнять, добавляя веса токенов и обязательные совпадения.
План действий:
- Загрузить оба каталога в Интеграм как отдельные таблицы
- Токенизировать названия — разбить на слова и записать в мульти-поле
- Сопоставить записи через пересечение токенов
- Улучшить точность с помощью весов и фильтров
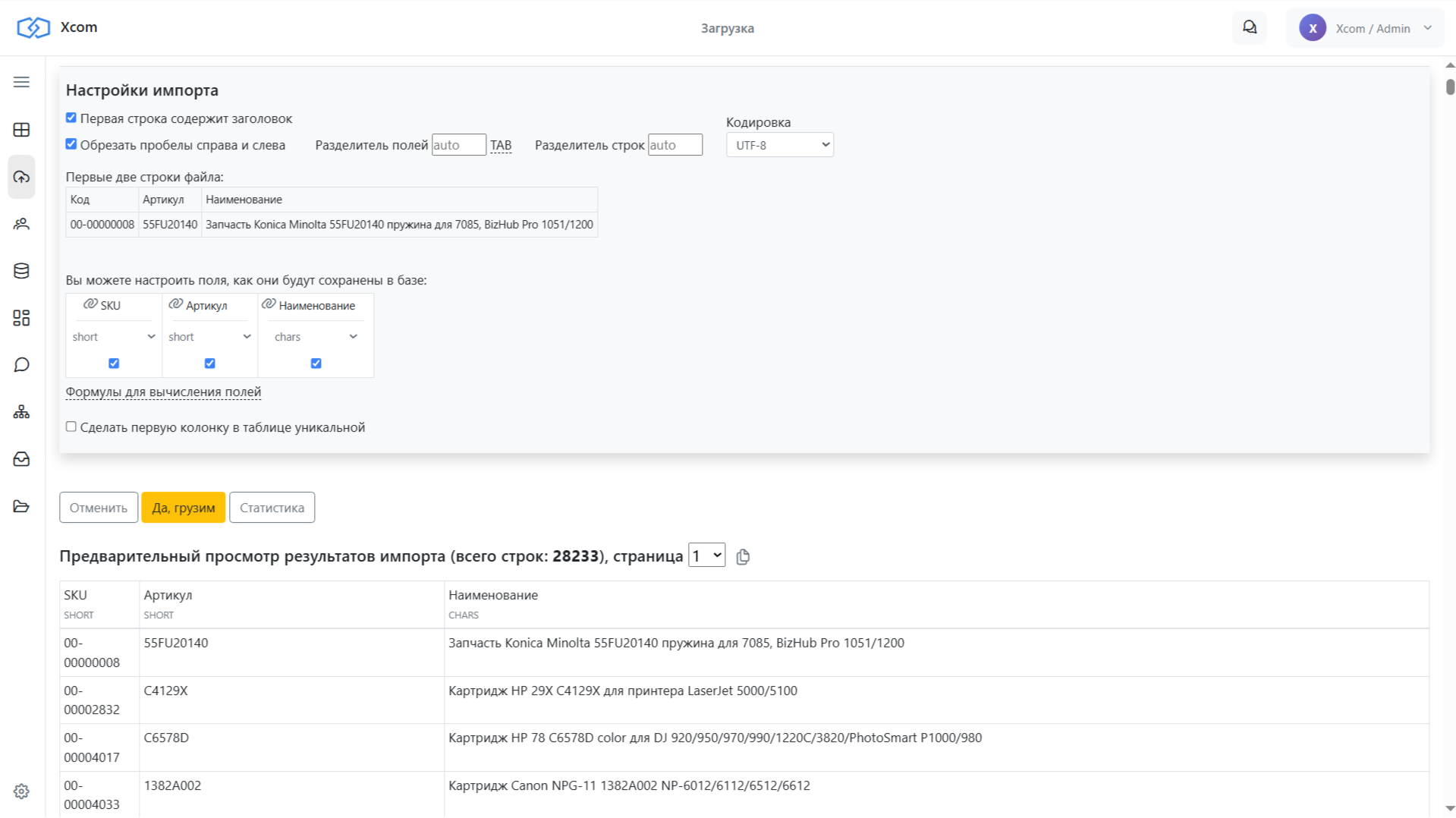
Шаг 1. Загрузка данных
Создаём новую базу данных в Интеграме. Через меню универсальной загрузки выбираем «Создать новые таблицы из файла» и копируем содержимое первого каталога.
Интеграм автоматически распознаёт структуру данных. Делаем пару настроек:
- Переименовываем таблицу в SKU (это наш внутренний каталог)
- Для поля «Наименование» убираем ограничение длины — меняем тип на «длинный текст»
Нажимаем «Загрузить» — данные пошли в таблицу.
Аналогично поступаем со вторым файлом. Здесь есть колонка «Бренд» — делаем её справочным значением. Таблицу называем RFP (Request for Proposal — предложение от контрагента).
Шаг 2. Добавление колонки для токенов
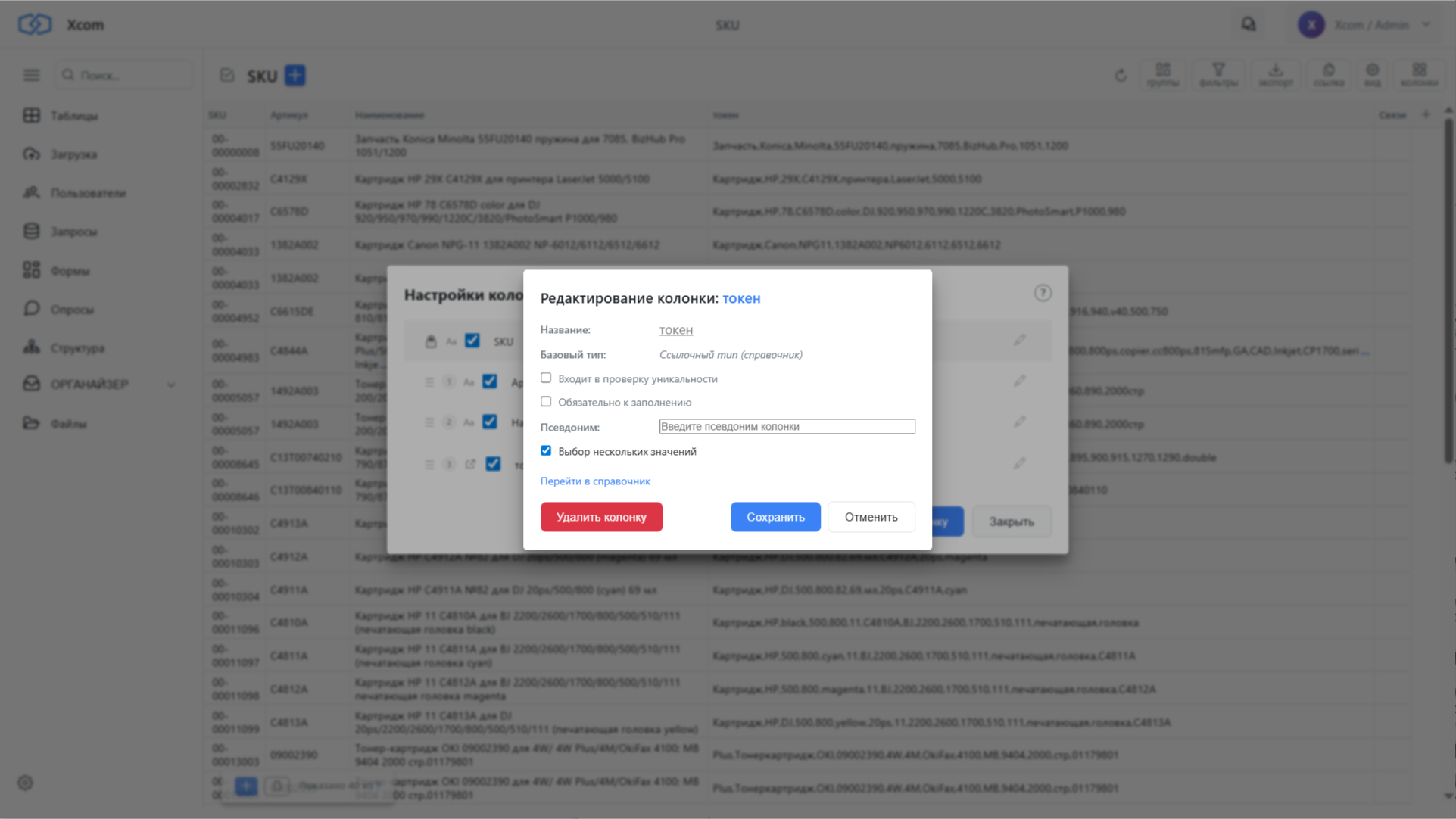
В таблицу SKU добавляем новую колонку:
- Имя: Токен
- Тип: ссылка на справочник
- Разрешён мультивыбор (одна запись может содержать несколько токенов)
Такую же колонку создаём в таблице RFP.
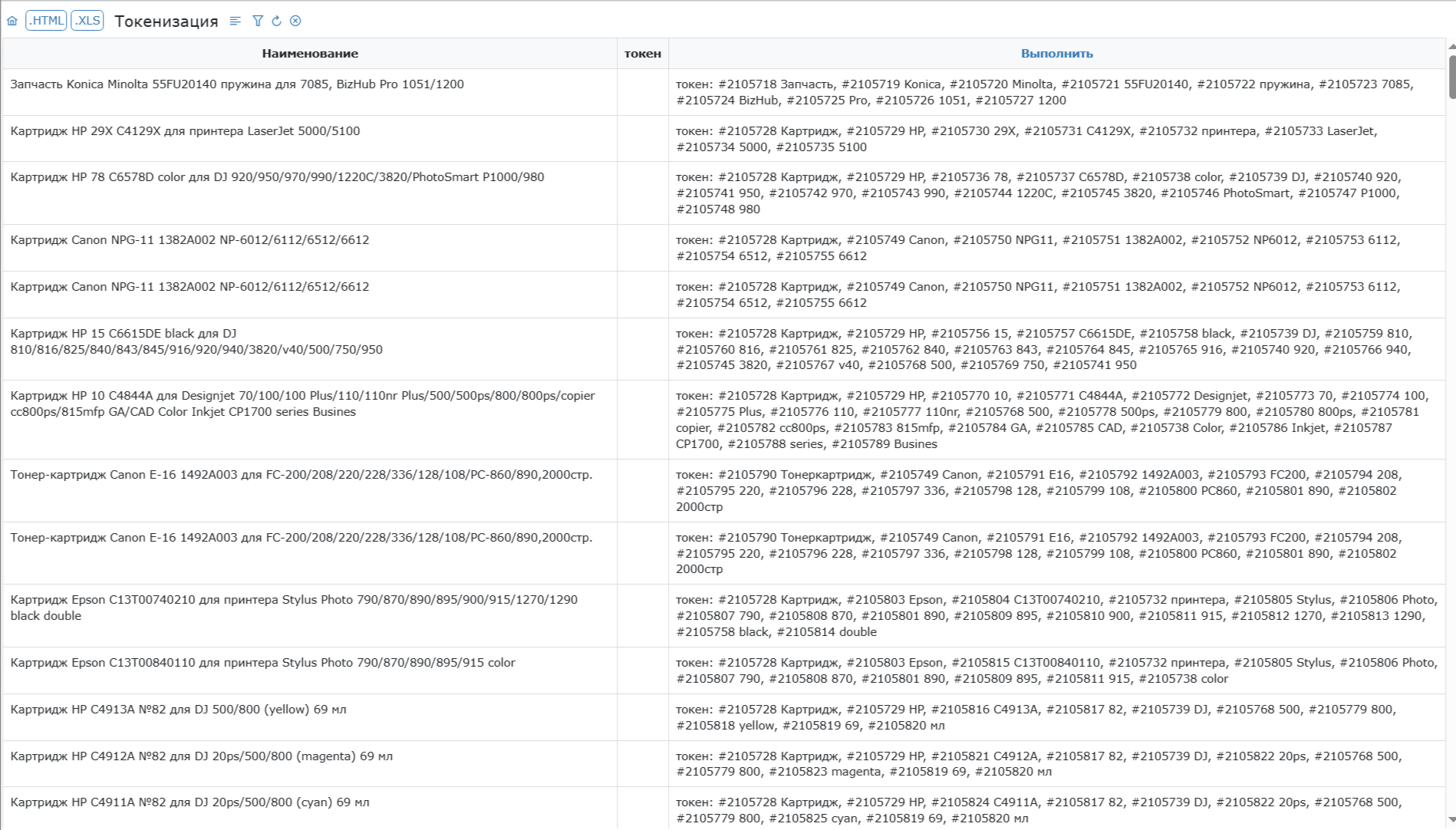
Шаг 3. Токенизация запросом
Теперь самое интересное. Создаём Запрос (в Интеграме это инструмент выборки и обработки данных). Назовём его «Токенизация».
В запросе три ключевые настройки:
- SELECT — выбираем поле «Наименование»
- WHERE — фильтр: «Токен не заполнен» (чтобы обрабатывать только новые записи)
- SET — присваиваем колонке «Токен» результат регулярного выражения
Регулярное выражение (подготовлено с помощью AI) разбивает наименование на слова, разделяя их запятыми:
REGEXP_REPLACE(
REPLACE(
REGEXP_REPLACE(
REGEXP_REPLACE(
REGEXP_REPLACE(
REPLACE(Наименование, '-', ''),
'[™№#"\'«»]', ''),
'(^| )(для|за|под|без|не|в|к|от|с|на|и)( |$)', ' '),
'[^a-zA-Z0-9а-яА-Я]+', ','),
',,+', ','),
'^,|,$', '')Ограничиваем выборку 10 000 записей — это комфортный объём для обработки в браузере. Запускаем запрос — через несколько секунд 10 тысяч наименований токенизированы.
Важно: Для таблицы RFP формулу нужно модифицировать — склеить Наименование и Бренд через пробел. В Интеграме это делает функция
CONCAT(Наименование, ' ', Бренд).
Повторяем запрос 2–3 раза для каждой таблицы, пока все записи не будут токенизированы. Пустой результат запроса означает, что всё готово.
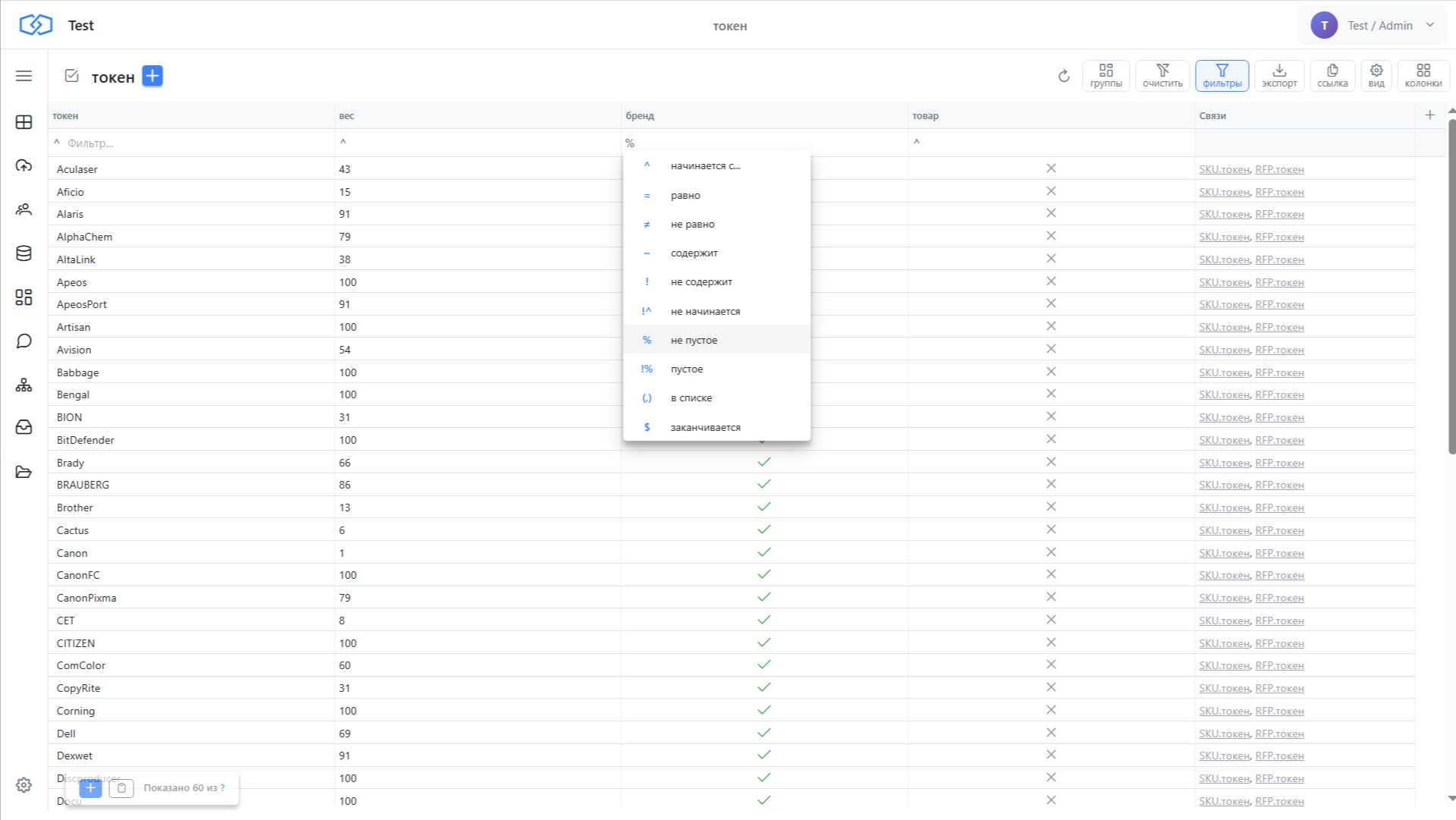
Шаг 4. Таблица токенов
В процессе токенизации Интеграм автоматически создаёт и наполняет справочник токенов — отдельную таблицу, где хранятся все уникальные слова. Токены используются одновременно в обеих таблицах (SKU и RFP), что и позволяет находить пересечения.
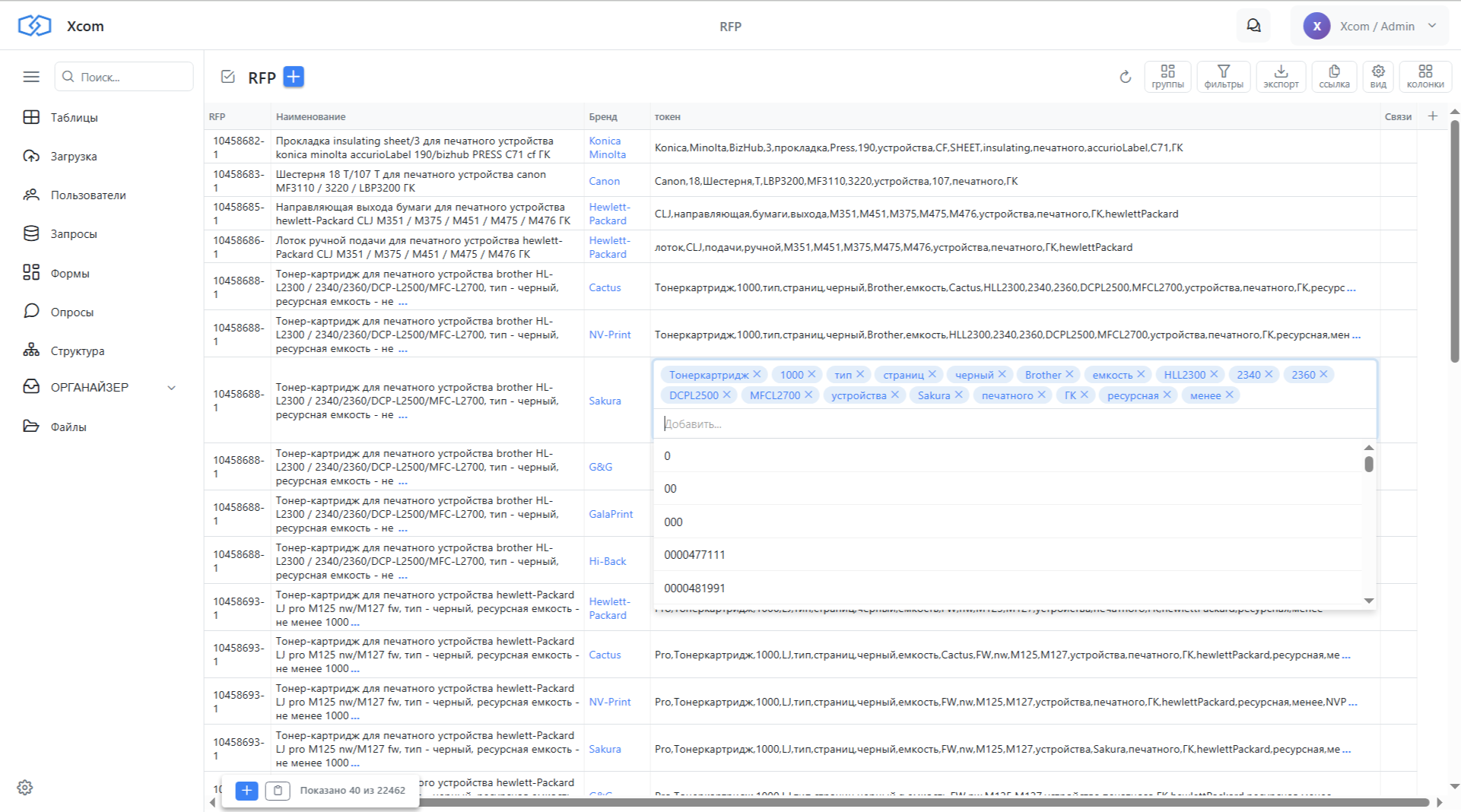
Шаг 5. Сопоставление через пересечение токенов
Теперь главный запрос — сопоставление. Выбираем одну позицию из каталога RFP и присоединяем (JOIN) таблицу SKU через общие токены. Каждая строчка одного каталога соединяется с каждой строчкой другого, если у них есть совпадающие токены.
Считаем количество совпавших токенов для каждой пары — это и есть наша оценка близости. Сортируем по убыванию: сверху оказываются позиции, у которых больше всего общих слов.
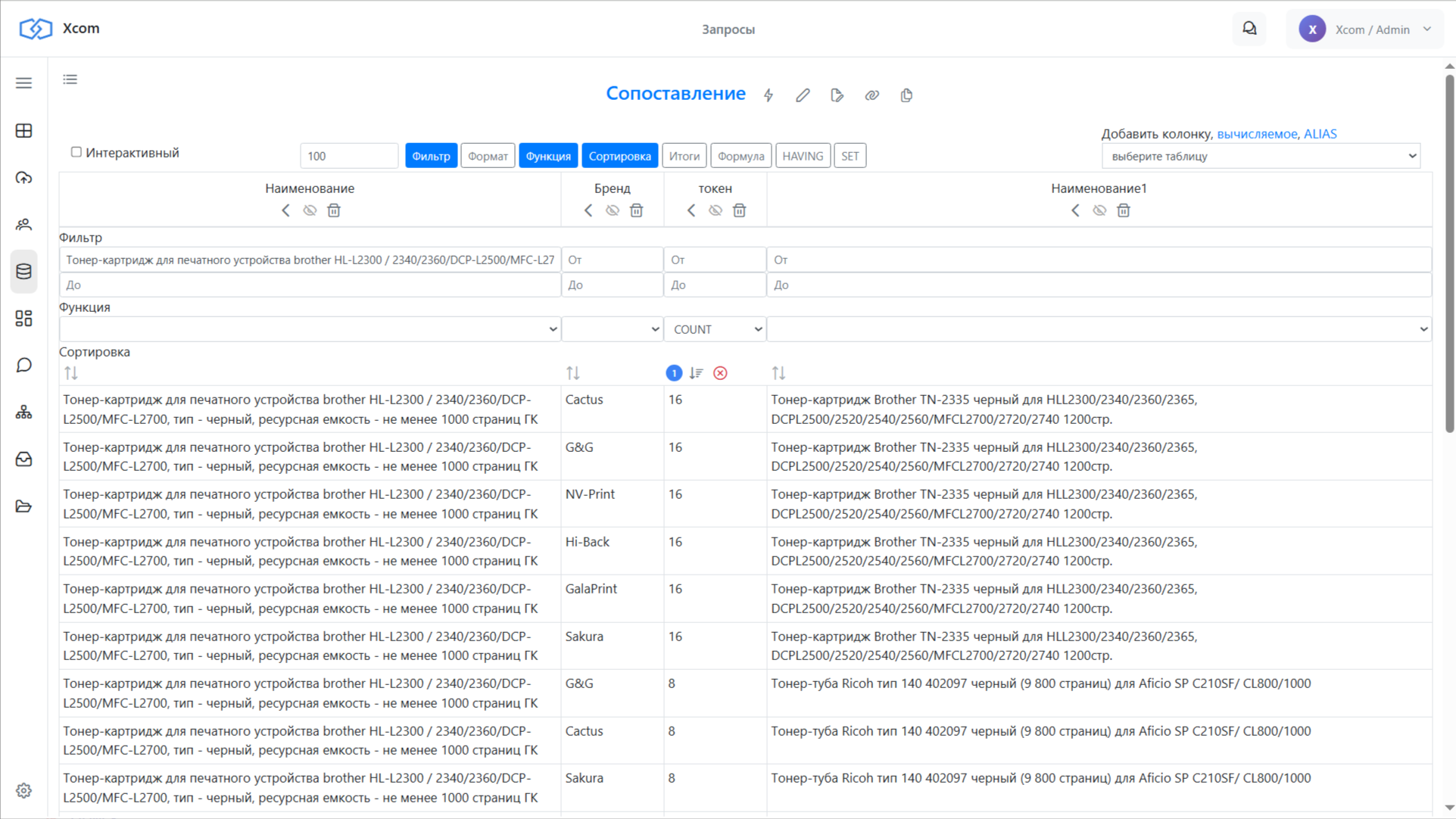
На скриншоте видно: тонер-картридж из каталога контрагента нашёлся в нашем каталоге, хотя называется иначе. 1200 страниц vs 1000 — но по составу токенов совпадение максимальное.
За 15 минут мы загрузили данные и получили первое сопоставление.
Шаг 6. Улучшение точности
Первое приближение работает, но его можно улучшить. Три доработки:
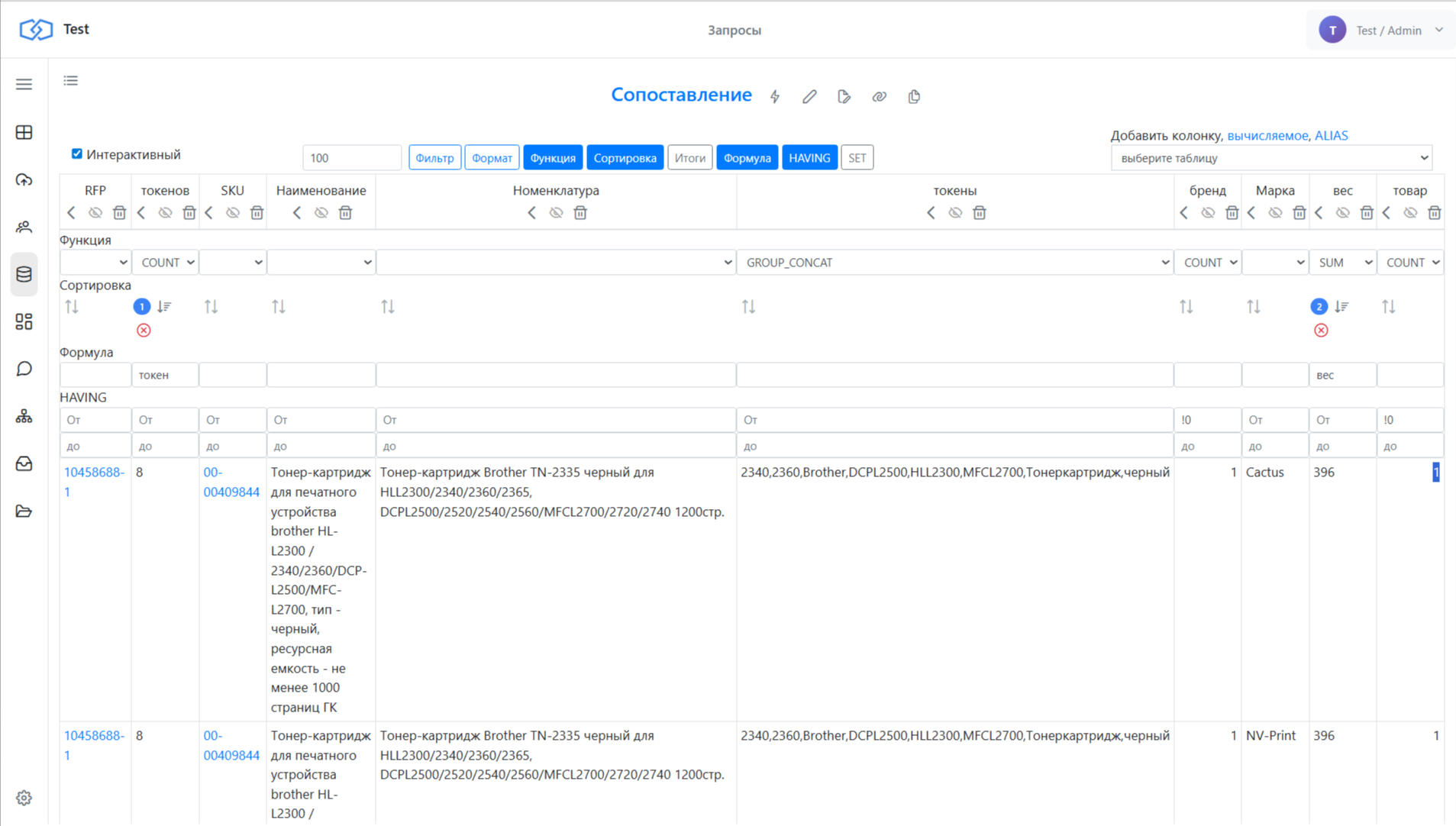
6.1. Вес токенов
Не все токены одинаково полезны. Слово «тонер» встречается часто — его вес должен быть ниже. Редкое слово-маркер — вес выше.
Добавляем запрос, который считает частоту каждого токена в таблице SKU, и записывает вес в справочник токенов. Затем при сопоставлении учитываем не только количество совпадений, но и сумму весов.
6.2. Обязательные совпадения
Размечаем токены флажками «Бренд» и «Товар». Это можно сделать с помощью AI — попросить DeepSeek или Claude проставить галки для списков брендов и типов товаров.
Теперь в запросе сопоставления добавляем условие: хотя бы один токен с галкой «Бренд» или «Товар» должен обязательно совпадать. Это резко повышает точность.
6.3. Сортировка по двум критериям
Сортируем результаты сначала по количеству совпавших токенов, затем по сумме весов. Так получаем максимально релевантные пары наверху списка.
Что дальше
В этом материале мы показали базу: как за 15 минут загрузить два каталога и сделать первое сопоставление. Продолжение уже вышло:
- Массовый автоматический подбор пар для всего каталога — в несколько потоков, с оценкой точности и доуточнением языковой моделью
- Более сложные алгоритмы нечёткого сравнения
- Интеграцию с внешними системами через API
Весь процесс не требует программирования — только понимание логики и умение составлять запросы в Интеграме. А регулярные выражения и разметку данных за вас сделает AI.
Попробуйте на своих данных. Это гораздо проще, чем кажется, и гораздо быстрее, чем вручную.